Mysql基本架构图
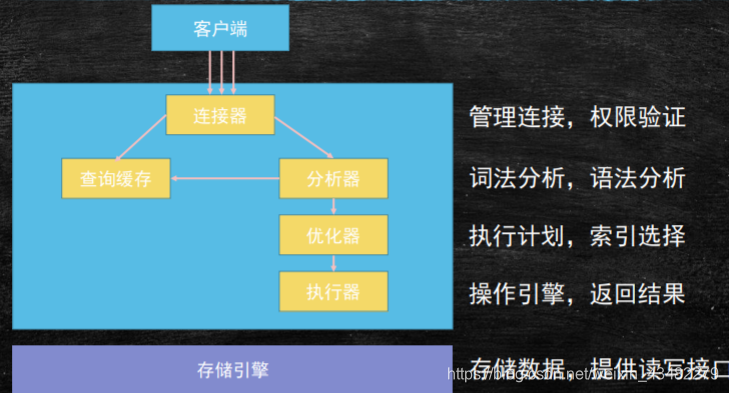
连接器:连接器负责跟客户端建立连接,获取权限、维持和管理连接。
▪ 可以使用show processlist查看现在的连接。
▪ 如果太长时间没有动静,就会自动断开,通过wait_timeout控制,默认8小时
▪ 连接可以分为:长连接和短连接。推荐使用长连接,可以提高性能。但是要周期性断开长连接,因为数量过多会占用过多资源。数据库连接池就属于长连接。分析器:词法分析:mysql把字符串识别成表名和列名;语法分析:根据语法规则判断是否合法。
查询缓存:之前查过的数据,会在这里进行一次缓存,如果之后还有一些相同的查询时,会直接从这里拿。平时写不常用是因为,一,这里面缓存失效比较频繁,也就是说,一旦数据库一旦发生改变,它就不能用了,缓存就会被清空。二,缓存对应新更新的数据命中率比较低。所以一般不用。mysql8.0后,取消了。
优化器:一般情况下,优化策略分为两个层面,一个叫RBO,基于规则的优化;一个叫CBO,基于成本的优化。现在更注重CBO,因为现在更多注重的是性能和效率。优化器是不可以省略的。这里是mysql自动帮我们优化,我们只需要写sql语句时,尽量让它能够走对应的优化策略,这也是我们查询执行计划的原因。这步之后,就形成详细的执行步骤。
包括,表中有多个索引的时候,决定用哪个索引;当sql语句需要做多表关联的时候,决定表的连接顺序等。执行器:直接执行。
日志
不管哪种日志其实就是一块内存区域事务实现ACID的底层实现机制是和日志挂钩的。
原子性是undolog保证的 undolog记录了数据操作前数据状态
持久化是redolog保证的 redolog记录更新之后数据状态
隔离性通过锁机制
Redo日志(前滚日志)——innodb存储引擎的日志文件
保证了持久性WAL(write ahead log,预写日志)为了提高性能的。如果每次修改数据都要写入磁盘,意味着要不停打开IO流。所以打算先写到内存中,合适时间再同步到磁盘中。但这时间段内如果断电不就东西消失了吗?所以维护的方式就是:每次先写到缓存空间里面,为了防止数据丢失问题,出现了redolog。
▪ 当数据发生修改的时候,innodb会先将记录写到redo log(有对应的内存空间),并更新内存,同时innodb会在合适时机将记录同步到磁盘。
▪ 有了redolog,innodb就可以保证即使数据库发生异常重启,之前的记录也不会消失,叫做crash-safe。
▪ 只要redolog完整,就能保证数据不丢失
▪ Redolog是固定大小的,是循环写的过程
每次write pos后面到checkpoint前面,这一块是可以写数据的。因为它们之间的部分还等待着checkpoint进行更新`。

既然要避免io,为什么写redo log的时候不会造成io的问题?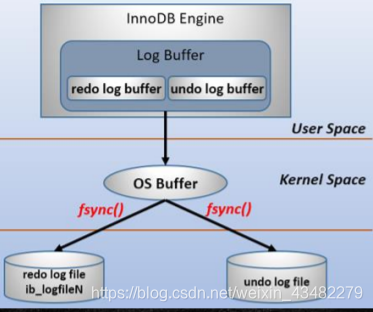
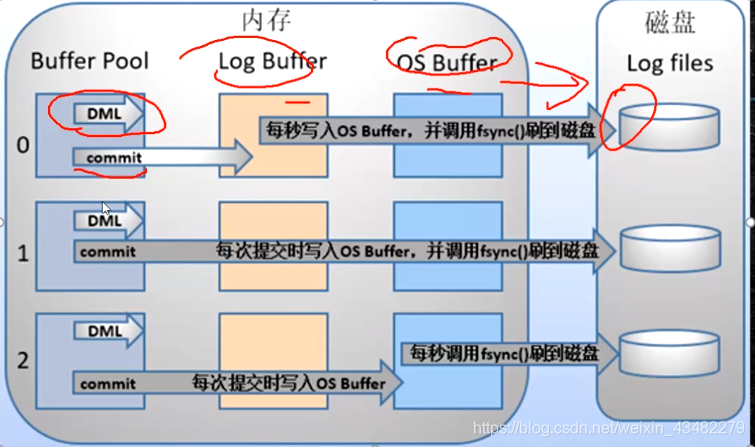
注意,虽然第1,3种也有不安全的地方,但是性能是比较高的,因为它们是批量操作。而第二种虽然最安全但是是单条操作。
类比案例 小卖铺每天买卖交易,每次从记账本中翻找很麻烦,于是每天在门口挂一个小黑板,记录今日交易,晚上统一誊写到记账本上。而小黑板大小有限,所以改变一下,一段时间就把黑板内容誊写到记账本上,然后擦除黑板内容,这就是redolog循环写的机制。
Undo log(回滚日志)——innodb存储引擎的日志文件
为了实现事务的原子性在进行操作数据之前,首先将数据备份到一个地方(这个存储数据备份的地方称为Undo Log),然后进行数据修改,如果要回滚,就可以利用备份数据恢复。
undo log其实是逻辑日志:
- 当delete一条记录时,undo log中会记录一条对应的insert记录
- 当update一条记录时,它记录一条对应相反的update记录
Binlog日志——服务端的日志文件
无关存储引擎,任何存储引擎都可以使用▪ Binlog是server层的日志,主要做的是做mysql功能层面的事情。
▪ 默认情况下mysql下binlog没开启。show variables like '%log_%'可以查找到一个log_bin选项,看是否开启。
▪ 与redo日志的区别:
- redo是innodb独有,binlog任何存储引擎都可以使用
- redo是物理日志,记录的是在某个数据页上做了什么修改,binlog是逻辑日志,记录的是这个语句的原始逻辑
- redo是循环写的,空间会用完,binlog是可以追加写的,不会覆盖之前的日志信息
▪ 一般企业数据库有备份系统,可以定期备份。恢复时,先找到最近一次的全量备份数据,然后从备份的时间点开始将备份的binlog取出来,重放到要恢复的那个时刻。
数据更新的流程
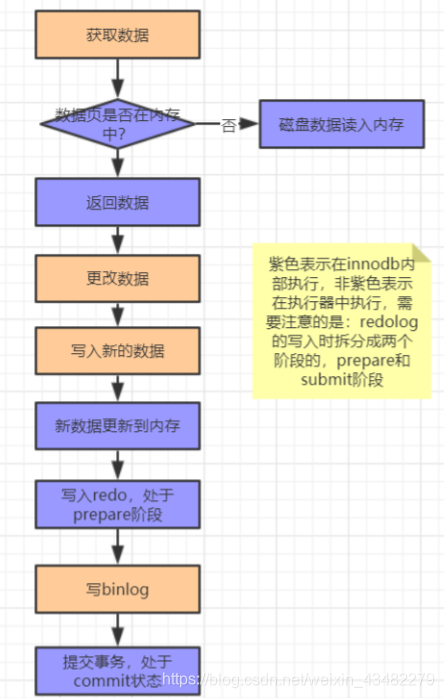
- 执行器先从引擎中查找数据,如果在内存中直接返回,如果没有再到磁盘中读取数据并返回
- 执行器更改数据,然后调用引擎接口重新吸入数据
- 引擎将数据更新到内存,同时写入redo中。并通知执行器执行生成
- 执行器生成这个事务的binlog
- 执行器调用引擎接口,引擎把刚写完的redo提交,更新完成。
Redo log的两阶段提交
为了保证redolog和binlog的数据一致性
▪ 先写redo log后写binlog:假设在redo log写完,binlog还没有写完的时候,MySQL进程异常重启。因为redolog后,系统即使崩溃也能把数据恢复回来,而binlog还没来得及写完,如果需要用这个binlog来恢复临时库,该临时库就会少了这一次更新,与原来库不同,所以不能先写。
▪ 先写binlog后写redo log:由于redolog还没写完,恢复后这个事务也无效。而binlog写完了,所以之后用它恢复临时库的时候就多了一个事务,所以也不行。