VIEW视图
▪ 视图(view),也称虚表,, 不占用物理空间,只有逻辑定义。
▪ 视图本身的定义语句还是要存储在数据字典里的。每次使用的时候, 只是重新执行SQL。
【给定一个sql语句,当每次用到的这个视图的时候,相当于把sql里面我们规定好的语句语句重新创建一下。】
▪ 视图是从一个或多个实际表中获得的,这些表的数据存放在数据库中。那些用于产生视图的表叫做该视图的基表。一个视图也可以从另一个视图中产生。
【比如,如果我们要查询雇员的名称和其所在部门的名称,意味着从emp表和dept表分别取出一个字段。这两个字段位于两张表,如果想组合进行使用的时候,可以把它定义成一个视图,下一次要查询的时候优先从这两张表里面做一个查询,查完后再进行一个实际操作】
▪ 视图的定义存在数据库中,与此相关的数据并不存在数据库中。通过视图看到的数据存放在基表中。
▪ 当通过视图修改数据时,实际上是在改变基表中的数据;相反地,基表数据的改变也会自动反映在由基表产生的视图中。由于逻辑上的原因,有些Oracle视图可以修改对应的基表,有些则不能(仅仅能查
询)。
【如果是只读视图,就不会修改基表的数据】
物化视图:<fontcolor=’red’>只在Oracle中有。会占用物理空间。如果基表中的数据更改了,视图中的数据也会更改,但是,它的更改是分两种方式的:
1.On DEMAND 仅在物化视图“需要”被刷新了,才进行刷新
2.ON COMMIT 一旦基表提交了数据,立刻刷新物化视图
创建视图
复杂的时候创建才有意义。
语法:
1 | CREATE [OR REPLACE] VIEW view |
1 | --创建视图 |
注:普通用户第一次使用,提示没有权限,要使用管理员去修改权限。只有在授权视图后才能创建成功。
授权视图
在cmd中登录管理员权限进行授权。
1 | C:\Users\Lenovo> sqlplus /nolog |
撤销权限SQL> revoke create view from scott;
使用视图
1 | select * from v_emp; |
向视图中添加数据,执行成功后,需要提交事务,绿色表示提交事务,红色表示回滚事务,让数据恢复原状态。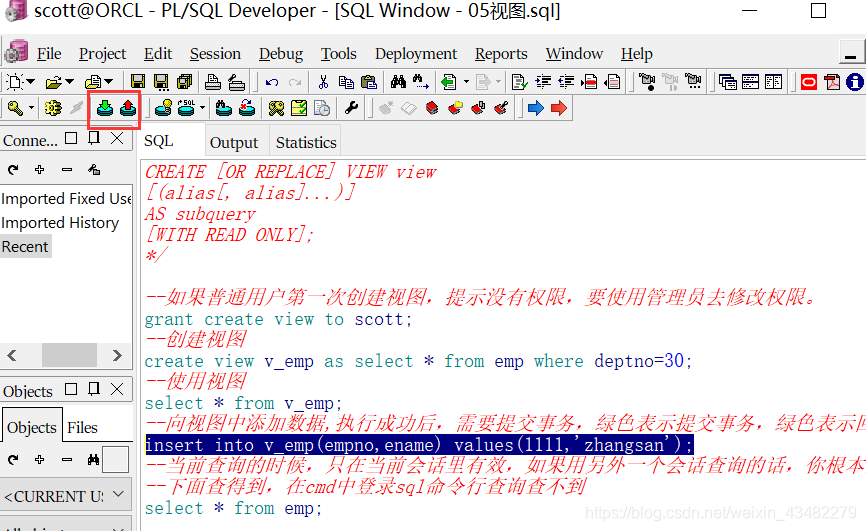
只读视图
如果定义的视图是非只读视图的话,可以通过视图向表中插入数据;如果是只读视图,则不可以插入数据。
1 | create view v_emp2 as select * from emp with read only; |
视图
▪ 在查询时,不需要再写完全的Select查询语句,只需要简单的写
上从视图中查询的语句就可以了.
▪ 当视图不再需要的时候,用“drop view” 撤销。删掉视图不会导致数据的丢失,因为视图是基于数据库的表之上的一个查询定义。
如果是物化视图,删除的也是对应物化视图的那份数据,不是我们原来基表里面的数据,没有影响。
1 | drop view v_emp2; |
修改视图对应基表数据
修改数据:
UPDATE view_name SET …
▪ 若一个视图依赖于多个基本表, 则一次修改该视图只能修改一个基本表的数据
删除数据:
delete from view_name where …
▪ 同样, 当视图依赖多个基表时, 不能使用此语句来删除基表中的数据,只能删除依赖一个基表的数据。
注:只是提供了这种操作而已,平时不要通过视图来修改和删除数据!没有意义。
例子:
我们要求平均薪水的等级最低的部门,它的部门名称是什么,我
们完全使用子查询。
1 | --1.求平均薪水 |
查看sql能够发现,sql中有很多重复的sql子查询,可以通过视图将重复的语句抽象出来。
1 | --创建视图 |
注意:公司中如果只使用一次就不需要使用视图,而多次使用的才会创建视图,不需要用完就删。
用户管理
- 创建用户
语法:create user username identified by password
红色字体为用户名密码。
create user bjmsb identified by bjmsb; - 查看用户是否创建
SQL>select username from dba_users;
创建好后不能直接登录会话。因为还没有授权。
用户授权
账户授权语法:
grant privileges [ON object_name] to username
将权限privileges授予用户usernameSQL>grant create session to John;
【授权:连接权限】
登录:SQL>conn John/johnpsw@test;
将scott用户的emp表所有权限授予John,则使用下列命令:SQL>grant all on scott.emp to John;select * from scott.emp
如果要收回授予用户John的scott用户表emp的所有权限,使用下列SQL语句:SQL>revoke all on scott.emp from John;
修改用户密码
将John用户的口令修改为 newpsw。SQL> alter user John identified by newpsw;
删除用户
使用drop user删除用户,关键字cascade删除用户模式中包含的数据对象
1 | 删除用户John,并同时删除John拥有的所有表、索引等对象。 |
查看自己的权限
select * from user_sys_privs;
序列sequence
序列是oracle专有的对象,用来产生一个自动递增的序列
create sequence seq_name
increment by n 每次增长n
start with n 从哪个值开始增长
maxvalue n|nomaxvalue 10^27 or -1 最大值
minvalue n|no minvalue 最小值
cycle|nocycle 是否有循环
cache n|nocache 是否有缓存
如果有缓存,就可以把一些序列值先存到缓存里面,下次用的时候直接用就行了,不至于做一个操作每次再递增一次。
序列的使用:
序列.nextval –>下个值
查看序列状态:
序列.currval –> 当前值
注意:如果创建好序列之后没有经过任何的使用,那么不能获取当前的值。必须先执行nextval才能获取当前的值
删除序列:
drop sequence 序列名;
1 | --创建 |
SQL数据更新
DML:数据操作语言
▪ Sql的数据更新包括数据插入、删除和修改3个操作
▪ 在实际项目中,使用最多的是读取操作,但是插入数据和删除数据同等重要,而修改操作相对较少
Insert语句
插入操作有两种方式:
1、元组值的插入,最基本的插入方式
2、查询结果的插入
▪ 如果有一个集合的数据,把集合中的所有数据都挨条插入的话,效率很低。
一、元组值的插入语法如下:
1、如果表名后没有列,那么只能将所有的列都插入
insert into tablename values(val1,val2,…);
2、可以指定向哪些列中插入数据
insert into tablename(col1,col2,…) values(val1,val2,…);
▪ 向部分列插入数据的时候,不是想向哪个列插入就插入的,要遵循创建表的时候定义的规范。要求省略的列必须满足下面的条件:
① 该列定义为允许Null值。
② 在表定义中给出默认值,这表示如果不给出值,将使用默认值。
如果不符合上面两个条件,将会报错。不能成功插入。
二、可以用insert语句把一个select语句的查询结果插入到一个基本表中,语法如下:
insert into tablename(col,..) select * from tablename2
例子:
1 | insert into emp values(2222,'haha','clerk',7902,to_date('2019-11-2','yyyy-mm-dd'),1000,500,10); |
DELETE语句
从基本表中删除满足条件表达式的元组。
元组,一组里面多个值
语法:
delete from tablename [where condition]
1 | --删除满足条件的数据 |
注意:
truncate跟delete不同,delete在进行删除的时候经过事务,而truncate不经过事务,一旦删除就是永久删除,不会回滚。效率高,但易发生误操作,不建议使用。
UPDATE语句
可以修改满足条件的一个列或者是多个列。
语法:
update tablename set co1 = val1, col2 = val2 where condition;
1 | --可以更新单列 |
事务处理
一、事务
▪ 增删改是数据库常用操作,在进行操作的时候都需要(事务)的保证,也就是说每次在plsql中执行sql语句之后都需要完成commit操作,所以事务变得非常关键。
▪ 最主要的目的是:最终为了保证数据一致性。
▪ 如果同一份数据,在同一时刻只能有一个人访问,就不会出现数据错乱的问题,但是在现在的项目中,更多的是并发访问,并发访问的同时带来的就是数据不安全,也就是不一致。
▪ 如果要保证数据的安全,最主要的方式就是加锁的方式,MVCC
▪ 事务的延伸:
最基本的数据库事务
声明式事务
分布式事务
▪ 为了提高效率,有可能多个操作会在同一个事务中执行,那么就有可能部分成功,部分失败,基于这样的情况就需要事务的控制。
select * from emp where id=7902 for update
select * from emp where id=7902 lock in share mode
▪ 如果不保证事务的话,会造成脏读,不可重复读,幻读。
事务(Transaction)是一个操作序列。这些操作要么都做要么都不做。是数据库环境中的逻辑工作单位。
▪ 事务是为了保证数据库的完整性。
▪ 事务不能嵌套。
比如转账操作,先从A卡里扣1000块,B卡中再增加1000块。所以等于一个操作里面有两个sql语句。其实实际过程中,可能包含n条语句。如果某一条语句失败,那么前面的语句必须进行一个回滚,回到原来的状态。所以必须要保证n条语句的绑定。这几条操作,合起来就被称为一个事务。
▪ 在oracle中,没有事务开始的语句。一个Transaction起始于一条
DML(Insert、Update和Delete )语句,结束于:
1、正常commit(使数据修改生效)或者rollback(将数据恢复到上一个状态)
2、自动提交,但是一般情况下要将自动提交自动关闭,效率太低
3、用户关闭,会话后会自动提交事务。例如退出scott时候,会将执行的语句提交
4、系统崩溃或断电时事务自动回滚事务,将数据恢复到上一个状态
二、commit&&rollback
commit:表示事务成功地结束,此把数据永久写到文件。
▪ 数据以前的状态永久性丢失
▪ 所有的用户都能看到操作后的结果
▪ 记录锁被释放,其他用户可以操作这些记录
rollback:表示事务不成功的结束,把缓存区的数据进行清除,恢复到数据以前的状态。
▪ 行级锁被释放
锁的机制:
为了解决并发访问的时候,数据不一致的问题,需要给数据加锁
加锁的同时需要考虑《粒度》的问题:
操作的对象
数据库
表
行
一般情况下,锁的粒度越细,效率越高;粒度越粗,效率越低
在实际工作环境中,大部分操作都是行级锁
▪ 它们都是另一个事务的开始。
1 | --可以sql命令提交/回滚,也可以按键提交/回滚 |
注:当前结果会提交到当前会话的一个缓冲区里面,commit之后,才会提交到某一个文件数据中。所以运行后当前会话可以查看到,但是别的会话不可以。
三、savepoint 保存点
当一个操作集合中包含多条sql语句,但是只想让其中某部分成功,某部分失败,此时可以使用保存点。
此时如果需要回滚到某一个状态的话,使用rollback to 保存点名称;
1 | --前两条sql语句成功执行提交,回退到删除1234这一条语句前,也就是这一条语句执行失败。 |
四、事务的四个特性:ACID
1、原子性(Atomicity):不可分割,一个操作集合要么全部成功,要么全部失败,不可拆分。
2、一致性(Consistency):为了保证数据的一致性,当经过n多个操作之后,数据的状态不会改变。从一个一致性状态到另一个一致性状态,也就是数据不可以发生错乱。
例如,转账业务最终金额总数不会变化
3、隔离性(Isolation):各个事务之间相关不会产生影响。(隔离级别)
严格的隔离性会导致效率降低,在某些情况下,为了提高程序的执行效率,需要降低隔离级别。
隔离级别:
读未提交
读已提交
可重复读
序列化
数据不一致的问题:
脏读
不可重复读
幻读
4、持久性(Durability):所有数据的修改都必须要持久化到达存储介质中,不会因为应用程序的关闭而导致数据丢失。
四个特性中,哪个是最关键的?
▪ 四个特性都是为了保证数据的一致性,所以一致性是最终的追求。
▪ 事务中的一致性是通过原子性、隔离性、持久性来保证的。
隔离级别
在同一个事务里面,不管你读了多少次数据,你的数据应该是一致的。
具体看《Mysql事务测试》
常用数据类型
- number(x,y) :数字类型 ,最长x位,y位小数
▪ Java中byte,short,long,int,float,double,boolean -> number - varchar2(maxlength):变长字符串,这个参数的上限是32767字节
▪ 声明方式如下VARCHAR2(L),L为字符串长度,没有缺省值,作为变量最大32767个字节 - char(max_length) 定长字符串 最大2000字节
- DATE:日期类型 (只能精确到秒。)
- TIMESTAMP:时间戳 (精确到微秒)
- long:长字符串,最长2GB
但没有人会往数据库里面放入2GB的数据,IO和性能是最大瓶颈。更多情况下会单独建一个图片服务器,而数据库里面只存放对应的路径即可。