SQL函数
【在api里面做一个基本查询就可以了】
函数一般是在数据上执行的,它给数据的转换和处理提供了方便。
只是将取出的数据进行处理,不会改变数据库中的值。
分类
SQL函数可以分为组函数和单行函数。
– 组函数(又称聚合函数),输入多个值,最终只会返回一个值
– 组函数仅可用于选择列表或者查询的having子句
where语句后面的只能是表中已有的字段,类似于sum(sal)这种的是不能被执行的。
– 单行函数,输入一个值,输出一个值
例如:
1 | select deptno,count(*) from emp group by deptno having count(*) >3; |
因为count()是在虚拟表里面,而并不存在于emp表中。所以如果把having换成where会报COU标识符无效。
注意:上面的count()不能取别名select deptno,c from emp group by deptno having c >3;也会报错
1 | --查询所有员工的薪水总和 |
单行函数
单行函数,输入一个值,输出一个值
分类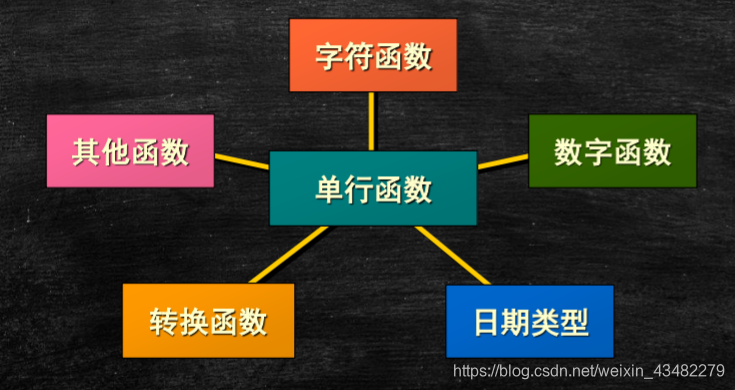
字符函数
字符函数全以字符作为参数,返回值分为两类:一类返回字符值,一类返回数字值。
– concat(string1,string2)连接两个字符串 ||
– initcap(string)string中每个单词首字母大写
– lower(string) 以小写形式返回string
– lpad,rpad 填充字符型数据
– ltrim/rtrim(string1,string2) 去左边/右部空格
– trim(A from B) 去空格
– Substr(string,x,y)提取字符串的一部分
x代表第几个位置
y代表长度
0和1的效果一样
用负数则从右边开始数第几个位置
– upper(string)以大写形式返回string
– Instr()字符串出现的位置
– Length()字符串长度
1 | --concat:表示字符串的连接,等同于 || |
数字函数
数字函数以NUMBER类型为参数返回NUMBER值。
负数在函数操作中也是支持的。
▪ round(number,n)返回四舍五入后的值
▪ trunc(number,n)
▪ mod(x,y)求余数
▪ ceil()上取整
▪ floor()下取整
▪ abs()绝对值
▪ sign(x)获取正负值 x=0,返回0;x<0,返回-1;否则返回1
▪ power(x,y)x的y次幂
1 | --进行四舍五入运算,可以指定小数部分位数 |
日期函数
Oracle以内部数字格式存储日期:世纪,年,月,日,小时,分钟,秒。
– sysdate/current_date 以date类型返回当前的日期
– Add_months(d,x) 返回加上x月后的日期d的值
– LAST_DAY(d) 返回的所在月份的最后一天
– Months_between(date1,date2) 返回date1和date2之间月的数目
1 | --获取当前系统时间 |
mysql中的日期函数
▪ select current_time() from dual;—- mysql:时间。
▪ select current_date() form dual; —mysql;日期
▪ select current_timestamp() from dual;—mysql:日期时间
转换函数
在oracle中,存在数值的隐式转换和显示转换。
隐式转换指的是字符串可以转换为数值或者日期。
1 | select '999'+10 from dual; -- 1009 |
尽管数据类型之间可以进行隐式转换,仍建议使用显示转换函数,以保持良好的设计风格。
显示转换指的是当由数值或者日期转换为字符串的时候,使用显示转换函数,必须规定格式。
▪ to_char
▪ to_number
▪ to_date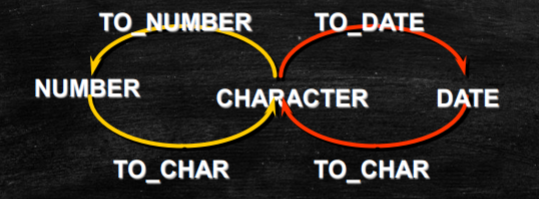
1、TO_CHAR(date, ‘fmt’)
用于将日期或时间戳转换成varchar2类型字符串,要指定格式字符串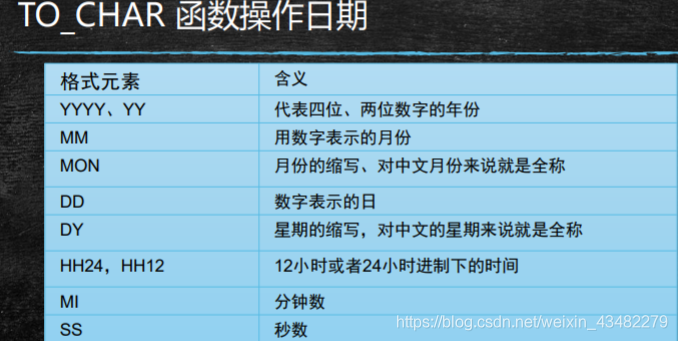
1 | --date:to_char |
2、to_char(num,format)
用于将Number类型参数转换为varchar2类型,要指定format
1 | --number:to_char |
3、to_date (String,format)
将char或varchar2类型的string转换为date类型
1 | select to_date('2019-10-10 10:10:10','YYYY-MM-DD HH24:MI:SS') from dual; --2019/10/10 10:10:10 |
4、to_number(String,format)
将char或varchar2类型的string转换为number类型
1 | select to_number('123,456.789','999,999.999') from dual; -- 123456.789 |
单行函数嵌套
案例:
1 | --显示没有上级管理(mgr为null)的公司首脑 |
其他函数
decode
decode(条件,值1,翻译值1,值2,翻译值2,…值n,翻译值n,缺省值)
功能】根据条件返回相应值
【参数】c1, c2, …,cn,字符型/数值型/日期型,必须类型相同或null
注:值1……n 不能为条件表达式,这种情况只能用case when then end解决
该函数的含义如下:
IF 条件=值1 THEN
RETURN(翻译值1)
ELSIF 条件=值2 THEN
RETURN(翻译值2)
……
ELSIF 条件=值n THEN
RETURN(翻译值n)
ELSE
RETURN(缺省值)
END IF
例子:
1 | --给不同部门的人员涨薪,10部门涨10%,20部门涨20%,30部门涨30% |
case when
case [<表达式>]
when <表达式条件值1> then <满足条件时返回值1>
[when <表达式条件值2> then <满足条件时返回值2>
……
[else <不满足上述条件时返回值>]]
end
【功能】当:<表达式>=<表达式条件值1……n> 时,返回对应 <满足条件时返回值1……n>
【参数】
<表达式> 默认为true (逻辑型)
<表达式条件值1……n> 类型要与<表达式>类型一致,
若<表达式>为字符型,则<表达式条件值1……n>也要为字符型
【注意点】
1、以CASE开头,以END结尾
2、分支中WHEN 后跟条件,THEN为显示结果
3、ELSE 为除此之外的默认情况,类似于高级语言程序中switch case的default,可以不加
4、END 后跟别名
5、只返回第一个符合条件的值,剩下的when部分将会被自动忽略,得注意条件先后顺序
例子:
1 | --给不同部门的人员涨薪,10部门涨10%,20部门涨20%,30部门涨30% |
组函数
组函数,一般情况下,组函数都要和group by组合使用
常用的组函数有5个:
▪ avg()返回某列的平均值,只适合数值类型的数据
▪ min()返回某列的最小值,适用于任何类型
▪ max()返回某列的最大值,适用于任何类型
▪ sum()返回某列值的和,只适合数值类型的数据
▪ count()返回某列的行数,处理的时候会跳过空值而处理非空值
注:
- group by,按照某些相同的值去进行分组操作
- group进行分组操作的时候,可以指定一个列或者多个列,但是使用了group by之后,选择列表中只能包含组函数的值或者group by的普通字段。 理解:按照部门进行分组后,每个部门里面的工资能一样吗?不能!所以sal根本查不出来了。
1
2
3
4
5
6-- 求每个部门的平均薪水
select deptno,avg(sal) from emp group by deptno;
--求平均薪水大于2000的部门
select deptno, avg(sal) from emp group by deptno having avg(sal) > 2000;
-- 报错,不是group by表达式
select sal, avg(sal) from emp group by deptno having avg(sal) > 2000; - 组函数仅在选择列表和Having子句中有效
- count一般用于获取表中的记录条数,获取条数的时候可以使用
*或者某一个具体的列,甚至可以使用纯数字来代替,但从效率角度考虑,建议使用数字或者某一个具体的列,而不要使用*效率太低。1
2
3
4--三种方式结果相同
select count(*) from emp;
select count(ename) from emp;
select count(1) from emp; - 组函数不能处理null
1
2select avg(comm) from emp; --分母只算不为空的条目
select avg(nvl(comm,0)) from emp; --分母为全部条目
数据分组
▪ 创建分组
– group by 子句
– Group by 子句可以包含任意数目的列。
▪ 除组函数语句外,select语句中的每个列都必须在group by 子句中给出。
– 如果分组列中具有null值,则null将作为一个分组返回。如果列中有多行null值,他们将分为一组。
– Group by 子句必须出现在where子句之后,order by 子句之前。
▪ 过滤分组(having子句)
– Where过滤行,having过滤分组。
– Having支持所有where操作符。
▪ 分组和排序
– 一般在使用group by 子句时,应该也给出order by子句
▪ 使用GROUP BY子句将表分成小组
▪ 出现在SELECT列表中的字段,如果出现的位置不是在组函数中,那么必须出现在GROUP BY子句中
▪ GROUP BY 列可以不在SELECT列表中
▪ 不能在 WHERE 子句中使用组函数.不能在 WHERE 子句中限制组. 使用Having对分组进行限制
Sql语句执行过程
 1、读取from子句中的基本表、视图的数据。
2、选取满足where子句中给出的条件表达式的元组
3、按group子句中指定列的值分组,同时提取满足Having子句中组条件表达式的那些组
4、按select子句中给出的列名戒列表达式求值输出
5、Order by子句对输出的目标表进行排序
1、读取from子句中的基本表、视图的数据。
2、选取满足where子句中给出的条件表达式的元组
3、按group子句中指定列的值分组,同时提取满足Having子句中组条件表达式的那些组
4、按select子句中给出的列名戒列表达式求值输出
5、Order by子句对输出的目标表进行排序
1 | --求部门下雇员的工资>1200的人的平均薪资,且大于2000的部门,按顺序排列 |
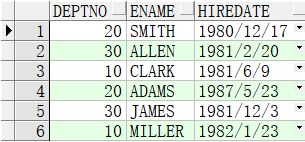
部门里面 工龄最小和最大的人找出来
1 | select deptno, min(hiredate), max(hiredate) from emp group by deptno; |
 如果想把对应的人名字列出来,怎么办?外面嵌套一层。
如果想把对应的人名字列出来,怎么办?外面嵌套一层。
1 | select ename,deptno from emp where hiredate in( |
1 | select ename, deptno |
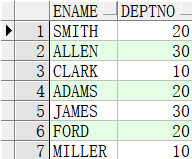 部门为20的有2个。为什么?因为FORD的雇佣日期是`1981/12/3`,刚好和30部门工龄最小的JAMES同一天。这样导致FORD也符合条件被打印出来了。所以我们要把部门也进行关联。但是我们发现in里面都是对应的子查询,没法写了。
部门为20的有2个。为什么?因为FORD的雇佣日期是`1981/12/3`,刚好和30部门工龄最小的JAMES同一天。这样导致FORD也符合条件被打印出来了。所以我们要把部门也进行关联。但是我们发现in里面都是对应的子查询,没法写了。
我们发现这种问题无法使用我们的子查询来解决了,需要用到两张表的关联查询。从而引入了关联查询。
1 | select mm2.deptno, e1.ename, e1.hiredate |
易错例子
1、查询员工的奖金,如果奖金不为NULL显示‘有奖金’,为null则显示无奖金。
1 | select ename, |
nvl(a, b) 当a!=null,才返回b。a,b类型要相同。
2、查询EMP表按管理者编号升序排列,如果管理者编号为空则把为空的在最前显示。
1 | select * from emp order by mgr nulls first; |
注意nulls first的使用。
3、按部门求出工资大于1300人员的 部门编号、平均工资、最小佣金、最大佣金,且最大佣金大于100。
1 | select deptno, avg(nvl(sal, 0)), min(comm), max(comm) |
Where过滤行,having过滤分组。
4、查询10号部门中编号最新入职的员工,工龄最长的员工的个人信息。
1 | select * |