读(Reader)进来(InputStream)(in) 写(Writer)出去(OutputStream/PrintStream)(out)
流表示一个文件将数据返送到另一个文件,包含一个流向的问题
当前所写的代码作为参照物:
从一个文件中读取数据到程序叫输入流
从程序写入文件叫输出流
字符是一个逻辑概念。
纯文本的,用字符流多一点,如果有图片,只能用字节流。

注意:每次编写IO流的时候一定要注意关闭流。原因:一个进程最多打开1024个文件。如果不关闭流对象,会占用系统资源,并发执行会卡死。
步骤:
- 选择合适的IO流对象
- 创建对象
- 传输数据
- 关闭流对象
节点流
字节流
处理图片、视频,其他文件格式的时候,最好还是使用字节流处理。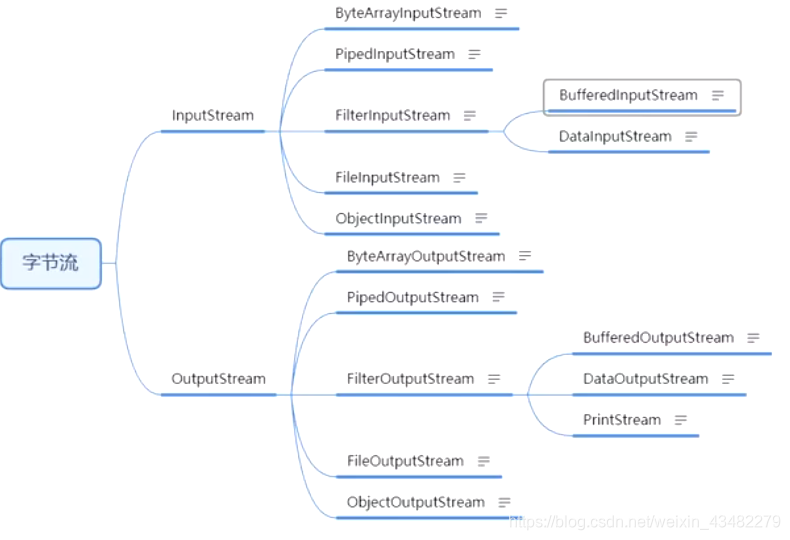
InputStream
FileInputStream
FileInputStream构造函数:FileInputStream(File file)
通过打开与实际文件的连接创建一个 FileInputStream ,该文件由文件系统中的 File对象 file命名。
字节流读取数据的方式:InputStream inputStream = new FileInputStream("abc.txt");
inputStream.read()返回值为数据的下一个字节,如果达到流的末尾, -1。每次读取一个字节。直接(char)强制类型转换进行字符读取。inputStream.read(byte[] b)返回值为读取到缓冲区的总字节数,已经到达流的末尾,那么 -1。添加缓冲区方式进行读取,每次将数据添加到缓冲区,满了之后一次读取,而不是每个字节读取。inputStream.read(byte[] b,off,len)返回值为读取到缓冲区的总字节数,已经到达流的末尾,那么 -1。第一个字节读取存储在元素b[off]…这些字节将存储在元素b[off]至b[off+ k -1]。
ByteArrayInputStream
ByteArrayInputStream包含一个内部缓冲区,其中包含可以从流中读取的字节。
1 | String str = "www.baidu.com"; |
OutputStream
FileOutputStream
字节流写入数据的方式:
1 | File file = new File("aaa.txt"); |
ByteArrayOutputStream
该类实现了将数据写入字节数组的输出流。
1 | ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream(); |
BufferedInputStream 和 BufferedOutputStream
BufferedInputStream构造方法:BufferedInputStream(InputStream in)
创建一个 BufferedInputStream并保存其参数(输入流 in) ,供以后使用
注:
- 一个BufferedInputStream为另一个输入流添加了功能。当创建好流对象后,在内部会创建一个内部缓冲区数组,当从流中读取或跳过(skip)字节时,内部缓冲区将根据需要从所包含的输入流中重新填充。
- 中文的时候必须用Reader,用字节流是没有办法进行处理的
1 | File file = new File("abc.txt"); |
读出的中文部分是乱码。
BufferedOutputStream构造方法:BufferedOutputStream(OutputStream out)
创建一个新的缓冲输出流,以将数据写入指定的底层输出流。
1 | File file = new File("123.txt"); |
DataInputStream 和 DataOutputStream
用来装饰其他输入流,以从底层输入流中读取基本java数据类型。即可以指定输入输出的类型。
1 | FileInputStream fileInputStream = null; |
ObjectInputStream 和 ObjectOutputStream (用的少)
序列化 :把Java对象转换为字节序列的过程
反序列化:字节序列–>Java对象
作用:(1)序列化:在传递和保存对象时,保证对象的完整性和可传递性。对象转换为字节流以便在网络上传输或者保存在本地文件中。
(2)反序列化:根据字节流中保存的对象状态和描述信息,通过反序列化重建对象。
核心:整个过程核心点就是字节流中所保存的对象状态及描述信息
注意:
如果需要通过io流进行传输,必须要实现以下两点:
- 实现序列化接口。
ObjectOutputStream使用writeObject()时,里面的自定义类必须实现Serializable,否则会保错。 - 需要在自定义类中声明
long serialVersionUID = 1L;这个值只是起标志作用,多少无所谓,只要写死就OK。
如果不想被人可见的属性比如密码,可以加上transient关键字。
transient:瞬时。使用它修饰的变量,在进行序列化的时候,不会被序列化。写入文件时,打开并没有密码,读取时候也不会显示。
通过ObjectOutputStream的write相关方法写入到文件中的,打开来会发现是乱码,人无法看懂。
字符流
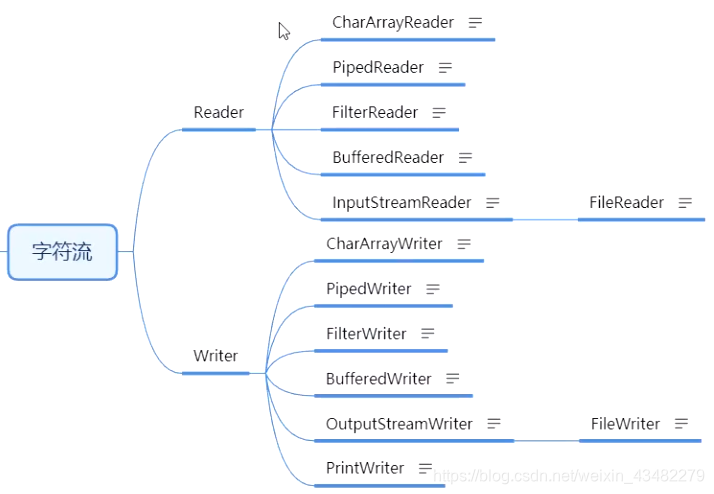
字符流读取数据的方式:
一个中文汉字占的字节数要看具体编码。
如果用字符流能够正确读出中文汉字,而字节流在处理的时候会出现中午文乱码。
1 | Reader reader = new FileReader("abc.txt"); |
// 读的是字符 int read = reader.read(); // 可以读取汉字 System.out.println((char)read); <!--7-->int length = 0; char[] chars = new char[1024]; while ((length = reader.read(chars)) != -1) { System.out.println(new String(chars,0,length)); } <!--8-->
注:什么时候需要加flush?
- 保险起见,在输出流关闭之前,每次都进行flush再关闭。
- 当某个输出流对象中带有缓冲区的时候就需要进行flush。
处理流
本来要按照一个字节一个字节进行处理,现在通过处理流在字节外包了一层,相当于是一个对应的字符了。现在处理的时候是按照字符为单位进行处理的,而不是再按照字节为单位的。
字符流优点
1)效率。如果是纯文本,用字符流处理效率相对是比较高的。
2)灵活性。如果用字符流进行输出的时候,在new的时候可以指定对应的编码格式。
InputStreamReader 是字节流通向字符流的桥梁:它使用指定的 charset 读取字节并将其解码为字符。
它使用的字符集可以由名称指定或显式给定,或者可以接受平台默认的字符集。
OutputStreamWriter 是字符流通向字节流的桥梁
InputStreamReader构造函数:InputStreamReader(InputStream in)
创建一个使用默认字符集的InputStreamReader。
处理流的使用
例如下面将字节流包裹后进行读写。关闭流对象时候建议按照创建时的逆序关闭。
2
3
outputStreamWriter = new OutputStreamWriter(fileOutputStream,"jbk");
outputStreamWriter.write(99);
2
3
4
5
6
inputStreamReader = new InputStreamReader(fileInputStream,"gbk");
// 数据较少无法占用1024个缓冲区时,不用循环方式,读取一次即可
char[] chars = new char[1024];
int len = inputStreamReader.read(chars);
System.out.println(new String(chars,0,len));
为什么需要这样的处理流?
网络传输的数据肯定是纯文本,此时获取到的就是InputStream或者OutputStream的对象。但它们都是根据字节流来处理的,非常低效。因为以知都是纯文本,所以我们包装成InputStreamReader或者OutputStreamReader对象,可以提高效率。
Socket中函数只有getOutputStream()和getInputStream(),没有getWriter(),getReader()。想要高效处理,需要在上面套字符流。