hashmap和hashtable的区别
- hashmap线程不安全,效率比较高,hashtable线程安全,效率低。
- hashmap中key和value都可以为空,hashtable不允许为空。
hashmap的初始值为2的n次幂,原因:
hash & (initCapacity - 1)分别进行 & 操作,提高效率, & 要比取模运算效率要高。
由于initCapacity - 1 是全1,这样数组下标 index 的值完全取决于 key 的 hash 值的后几位。如果不是全1,那么按位与的时候,容易发生哈希碰撞。
在扩容之后涉及元素的迁移过程,迁移的时候只需要判断二进制的前一位是0或者是1即可。
如果是0,表示新数组和旧数组的下标位置不变,如果是1,只需要将索引位置加上旧的数组的长度值即为新数组的下标。
1.7 hashmap的源码分析: 数组+链表
- 默认初始容量
- 加载因子
- put操作
1)设置值,计算hash
2)扩展操作
3)数据迁移的过程
private void inflateTable(int toSize)
`capacity` : hashmap的初始值,为2的n次幂
`threshold = capacity * loadFactor` : loadFactor是加载因子,每次进行扩容的时候会用到。如果capacity = 16,loadFactor = 0.75,那么当容量为12的时候我们可以进行扩容。
`table = new Entry(capacity)` 在堆里面创建一个数组空间,我们可以往里面放入元素值了。
if(key == null)
为了减少哈希碰撞关于 |= , &= , ^= 运算符
a |= b:相当于“a ∪ b” 只有a,b二进制位均为0时,结果才为0
a &= b:相当于“a ∩ b” 只有a,b二进制位均为1时,结果才为0
a |= b:相当于“a异或b” 只有a,b二进制位相异,结果才为0
1.8 hashmap的源码分析:数组+链表+红黑树
扰动函数:让高位参与运算来减少哈希碰撞发生的概论。1.8之后,当链表长度过长(默认超过了8),就转为红黑树。
问题
问题一:对HashMap 构造方法中 initialCapacity(初始容量)、loadFactor(加载因子)的理解?
初始容量代表了哈希表中table数组的初始长度,默认是16,如果自定义,会通过方法保证每次初始容量为2的n次幂。
加载因子衡量了散列表的空间使用程度,加载因子越大,对空间利用越充分,但是越容易发生hash碰撞。默认0.75。
如果当前存储数量超过了阈值【初始容量 * 加载因子】,就要进行扩容操作。
问题二: JDK1.7 中 HashMap 什么情况下会发生扩容?如何扩容?
扩容必须满足两个条件:
- 存放新值的时候当前已有元素必须大于等于阈值;
- 存放新值的时候当前存放数据发生hash碰撞
所以在第一次扩容时候,最少存到了16个键值对,最多能存到26个键值对
不超过阈值时候,每次都存到同一个位置,最多存了11个;第12个开始,后面15个没有发生哈希碰撞,所以一共能存27个才发生扩容。
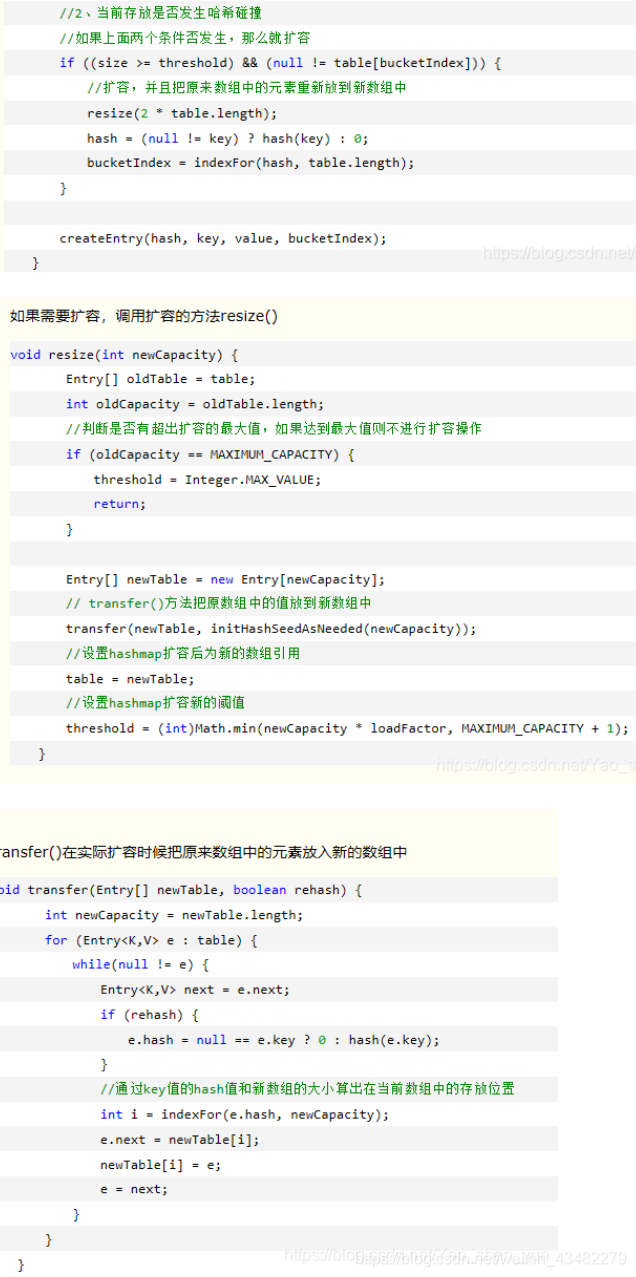
如果满足扩容条件,调用扩容的方法:把原数组中的值放到新数组中。然后设置hashmap的新阈值(threshold):newCapacity * loadFactor。新容量=2 * oldCapcity
元素迁移过程:
- 通过key值的hash值和新数组的大小,计算出在当前数组中的位置。
- 因为数组扩大了两倍,迁移的时候只需要判断二进制的前一位是0或者是1即可。如果是0,新数组中位置就是旧数组的位置;如果是1,新数组中的位置就是旧数组的位置再加上数组的长度。
- 取出数组元素,遍历链表。原来hash冲突的链表尾部变成了新数组元素中,链表的头部。