第一章 数据结构
常用数据结构:
- 栈结构:先进后出
- 队列:先进先出
- 数组:查询快,增上慢。
注:在堆内存中,频繁创建数组复制数组中的元素,销毁数组,效率低下。 - 链表:查询慢,增删快。
单向链表:一条链,不能保证元素顺序(存储/取出元素顺序)【无序】
双向链表:两条链,有一条是专门记录元素的顺序【有序】 - 红黑树
特点:趋近于平衡树,查询速度非常快,查询叶子节点最大次数和最小次数不能超过2倍。
约束:
1.节点可以是红色或黑色
2.根节点是黑色的
3.叶子节点必须是黑色的
4.每个红色的节点的子节点都是黑色的
5.任何一个节点到其每一个叶子节点的所有路径上黑色节点数相同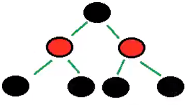
第二章 List集合
java.util.List 接口继承自 Collection 接口· 特点:
1. 有序的集合(存储、取出元素顺序相同)
2. 有索引,包含了一些带索引的方法
3. 允许存储重复元素
· List接口中带索引的方法(特有)
public void add(int index, E element): 将指定的元素,添加到该集合中的指定位置上。public E get(int index):返回集合中指定位置的元素。public E remove(int index): 移除列表中指定位置的元素, 返回的是被移除的元素。public E set(int index, E element):用指定元素替换集合中指定位置的元素,返回值的更新前的元素。
注:使用索引,防止索引越界异常
IndexOutOfBoundException:索引异常,集合会报
ArrayIndexOutOfBoundException:数组索引异常
StringIndexOutOfBoundException:字符串索引异常
2.1 List的实现类
2.1.1ArrayList集合
· List接口的大小可变数组的实现。即底层是一个数组结构。查询快,增删慢。
· 此实现不是同步的。
注:不是同步的,就是多线程的。多线程速度效率高。
2.1.2 LinkedList集合
`java.util.LinkedList` 集合 implements List接口· 特点:
- 底层是一个链表结构。查询慢,增删快
- 此实现不是同步的
- 里面包含了大量操作首位元素的方法
注:使用该集合特有的方法,不能使用多态。
-public void addFirst(E e):将指定元素插入此列表的开头。
-public void addLast(E e) :将指定元素添加到此列表的结尾。【与add()方法等效】
-public void push(E e):将元素推入此列表所表示的堆栈。【与addFirst()等效】
-public E getFirst() :返回此列表的第一个元素。
-public E getLast():返回此列表的最后一个元素。
(如果没有元素,报错NoSuchElementException,可用isEmpty()进行判断)
-public E removeFirst():移除并返回此列表的第一个元素。
-public E removeLast():移除并返回此列表的最后一个元素。
-public E pop() :从此列表所表示的堆栈处弹出一个元素。
【与 removeFirst()等效】
-public boolean isEmpty():如果列表不包含元素,则返回true。
2.1.3 Vector集合
· 底层是一个数组。开始于JDK1.0,是所有单列集合的祖宗。
· 同步的,意味着是单线程的,速度慢。所以1.2版本后被ArrayList取代
第三章 Set接口
java.util.Set 接口 extends Collection 接口
· 特点:
- 不允许存储重复元素
- 没有索引,没有带索引的方法,也不能使用普通的for循环遍历
第三章 Set接口
3.1 Set接口的实现类:
3.1.1 HashSet集合
`java.util.HashSe`t implement `Set` 接口· 特点:
- 不允许存储重复元素
- 没有索引,没有带索引的方法,也不能使用普通的for循环遍历
(可以使用迭代器遍历,增强for遍历) - 无序集合,存储、取出元素顺序有可能不一致
- 底层是一个哈希表结构,查询速度很快
- 此实现不同步
3.1.2 HashSet集合存储数据的结构(哈希表)
哈希值
一个十进制整数,没有重写由系统随机给出(就是对象的地址,是逻辑地址,不是实际存储的物理地址)
· 在Object类中有个方法,可以获取该对象的哈希值。
int hashCode()- 方法源码:注:
1
public native int hashCode();
native:代表该方法调用的是本地操作系统的方法 - 可以在对象中重写该方法,这时候,尽管对象的地址值相同(可以直接输出对象实例来查看),但是“==”判断是false。因为实际物理地址是不同的。
- String类重写了Object类的hashCode方法。字符串相同,哈希值相同。但是字符串不相同,哈希值可能相同。
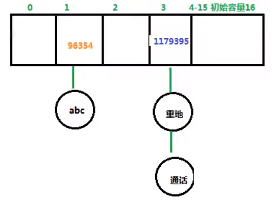
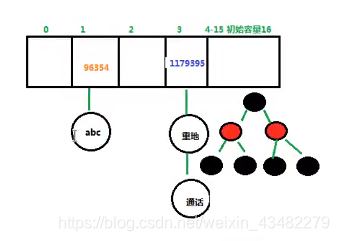
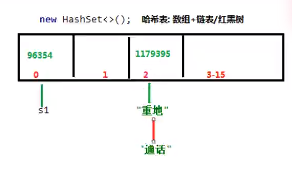
e.g “abc”:96354; “重地”,“通话”:1179395
· 哈希冲突:两个元素不同,但是哈希值相同
哈希表
JDK1.8之前,哈希表=数组+链表
JDK1.8之后:
哈希表=数组+红黑树; (提高查新速度)
哈希表=数组+链表数组结构把元素进行分组,相同哈希值的元素是一组,链表/红黑树结构把相同哈希值的元素链接在一起。
数组的初始容量为16。存储数据到集合中:
1)计算元素哈希值
2)先分组,再下挂。
JDK1.8之后,如果下挂的元素超过了8位,就会把链表转化为红黑树结构。为了提高查询速度
3.1.3 Set集合不允许存储重复元素的原理
· 前提: 存储的元素必须重写hashCode方法和equals方法
· 过程:
e.g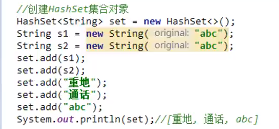
· set.add(s1);
- add()方法会调用要存储对象“s1”的
hasCode方法,计算字符串“abc”的哈希值是96354 - 在集合中找是否有96354这个哈希值的元素,发现没有
- 把s1存储到集合中
· set.add(s2);
- add()方法会调用要存储对象“s2”的
hasCode方法,计算字符串“abc”的哈希值是96354 - 在集合中找是否有96354这个哈希值的元素,发现有
- s2会调用equals方法和哈希值相同的元素进行比较
s2.equals(s1);,返回true - 两个元素哈希值相等,还返回了true,认定两个元素相同
- 不会把s2存储到集合中。
· set.add("重地");
- add()方法会调用要存储对象“重地”的
hasCode方法,计算字符串“重地”的哈希值是1179395 - 在集合中找是否有1179395这个哈希值的元素,发现没有
- 把”重地”存储到集合中
· set.add("通话");
- add()方法会调用要存储对象“通话”的
hasCode方法,计算字符串“通话”的哈希值是1179395 - 在集合中找是否有1179395这个哈希值的元素,发现有
- “通话”会调用equals方法和哈希值相同的元素进行比较
"通话".equals("重地");,返回false - 两个元素哈希值相等,还返回了false,认定两个元素不同
- 就会把”通话”存储到集合中
3.1.4 HashSet存储自定义类型元素
· 要求:之前存储的String、Integer等,已经重新了hashCode和equals方法。如果要存储自定义类型元素,必须要自己重写这两个方法。
【IDEA中,alt+insert进行重写】
· 没有重写hashCode方法,两个相同的元素,哈希值也不同,所以equals返回的也是false。(没有重写,比较的是地址值)
3.2 LinkedHashSet集合
java.util.LinkedHashSet集合 extends HashSet集合
特点:
底层是一个哈希表(数组+链表/红黑树)+链表(记录元素的存储顺序),保证元素有序
3.3 可变参数
JDK1.5出现的新特性· 使用前提:当方法的参数列表数据类型已经确定,但参数的个数不确定,就可以使用。
· 使用格式:定义方法时使用
修饰符 返回值类型 方法名(数据类型... 变量名){ }
· 特殊(终极)写法:修饰符 返回值类型 方法名(Object... obj){ }
· 原理:- 底层就是一个数组,根据传递参数的个数不同,会创建不同长度的数组,来存储这些参数。
- 传递的参数个数可以是0,1,2…
e.g 定义计算(0~n)整数和的方法
1 | public static int add(int…arr) { |
注:‘[’代表数组,‘I’是指int类型,@后是地址值
如果调用add();,会创建一个长度为0的数组,new int[0]
如果调用add(10);,会创建一个长度为1的数组,new int[1]
如果调用add(10,20);,会创建一个长度为2的数组,new int[2]
……
· 注意事项:
- 一个方法的参数列表,只能有一个可变参数
- 如果方法的参数有多个,那么可变参数必须写在参数列表末尾
第四章 Collections
` java.utils.Collections 是集合工具类,用来对集合进行操作。部分方法如下:
- public static
- public static void shuffle(List<?> list) 打乱顺序 :打乱集合顺序。
- public static
- public static
序。
e.g
1 | ArrayList<String>color=newArrayList<>(); |
注:
- 静态方法,直接使用类名(Collections)调用即可。
- 无论是Interger还是String,都实现了一个接口Comparable,实现这个接口的目的是重写里面的compareTo()方法(排序方法),重写后,才能按照自己的规则来排序。
所以sort(List<T> list)使用前提:被排序的集合中存储的元素,必须实现comparable,重写接口中方法compareTo定义排序规则。
重写自定元素类型中compareTo方法,默认返回0(认为元素都是相同的)。comparable排序规则:自己(this)- 参数 :升序
· sort(List
e.g
//排序方法 按照第一个单词的降序
Collections.sort(list, new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
return o2.charAt(0) ‐ o1.charAt(0);
}
}
· comparable和comparator的区别:
1. comparable:自己(this)和别人(参数)的比较。自己需要重写comparable接口,重写比较的规则compareTo方法。
2. comparator:相当于找一个第三方的裁判,比较两者
注:comparator的compare方法排序规则:o1-o2 升序